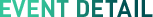High-quality Embodied Intelligence Datasets around the world at present
In the evolutionary trajectory of artificial intelligence, embodied intelligence has emerged as a captivating frontier, signifying a pivotal shift in AI technology. It marks the transition from a reliance on mere computation and logical inference to a profound integration with the physical world. By equipping intelligent agents with physical forms and perceptive faculties, embodied intelligence empowers them to perceive, reason, make decisions, and execute tasks within real-world contexts. This advancement not only broadens the application horizons of AI but also drives the evolution of robotics from performing single, specialized tasks to handling multifaceted, general-purpose operations.
In the domain of humanoid robotics, numerous enterprises are strategically positioning themselves for growth. Industry leaders like Tesla, Boston Dynamics, and UBTECH are at the vanguard of technological innovation and market expansion. The Chinese market, in particular, boasts distinctive advantages in policy support, technological R&D, market demand, and supply chain infrastructure. Chinese enterprises are leveraging these strengths to carve out a significant niche in global competition.
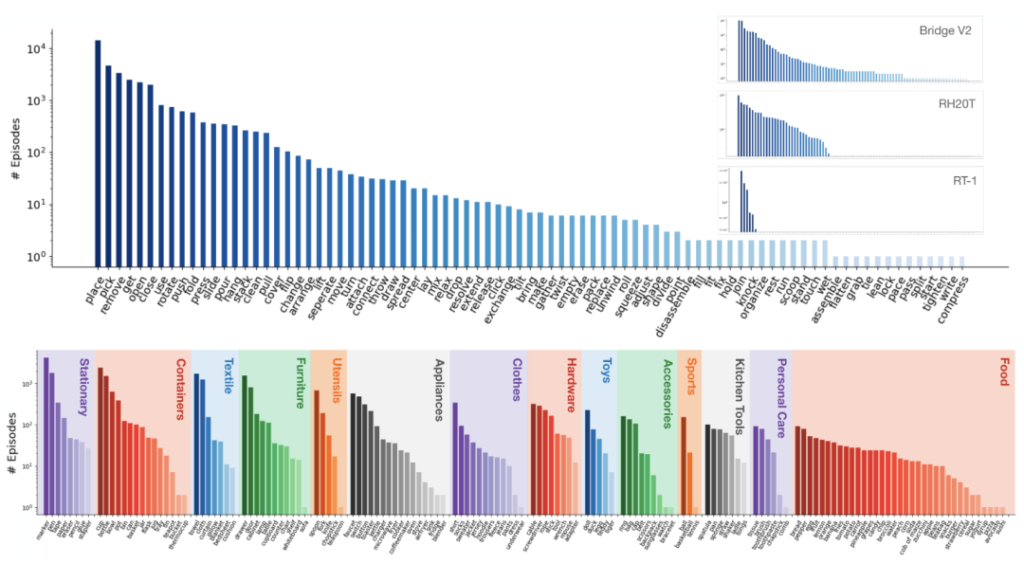
Amidst the rapid industrial progression, data has emerged as a linchpin in the development of embodied intelligence. High-quality datasets serve as invaluable repositories of knowledge, enabling robots to gain a deeper understanding of complex environments and tasks. This, in turn, significantly enhances their operational performance and generalization capabilities. However, the construction of such datasets remains fraught with challenges. Issues such as limited data volume, inconsistent data quality, the absence of unified standards, and the prevalence of data silos pose substantial obstacles, impeding the further advancement of embodied intelligence technology.

Against this backdrop, research institutions and enterprises worldwide are dedicating themselves to the construction and optimization of datasets for embodied intelligence. From Google’s Open X-Embodiment to the AgiBot World of Zhiyuan Robotics, these datasets have made continuous breakthroughs in terms of scale, diversity, and quality, providing strong support for the research and application of embodied intelligence technology. These datasets not only cover a variety of task types and scenarios but also integrate multimodal information, such as vision, haptic feedback, audio, and language, providing a comprehensive data foundation for the perception and decision-making of robots. This article will provide a detailed introduction and analysis of the major global datasets for embodied intelligence, sorting out their basic information and core characteristics, aiming to provide valuable references for researchers and practitioners in relevant fields. Note: The content of the following article is a preliminary comprehensive compilation based on publicly available information, and the content is for reference only. In case of any errors or omissions, please understand. For more detailed and specific content, please refer to the official announcements or papers of each institution.
01
AgiBot World
AgiBot World is the world’s first million-scale real-machine dataset based on global real-world scenarios, an all-around hardware platform, and full-process quality control. It is jointly launched by Chinese company Zhiyuan Robotics, Shanghai AI Laboratory, the National and Local Joint Innovation Center for Humanoid Robots, and other institutions. Its goal is to drive breakthroughs in the field of Embodied AI, address the industry pain points of scarce and costly training data for robots, and accelerate the development of Artificial General Intelligence(AGI).

Data Volume: It contains more than 1 million real robot action trajectories, involving over 100 robots of the same configuration, covering five core scenarios including home, catering, industry, supermarkets, and offices, and encompassing more than 80 kinds of daily life skills (such as grasping, stirring, folding, etc.).
Scene Diversity: It replicates more than 100 real-world scenes, includes over 3,000 kinds of real items, and long-term tasks with a duration ranging from 60 to 150 seconds account for 80%, which is more than 10 times that of traditional datasets (such as DROID and Open X-Embodiment). The data collection relies on the 4,000-square-meter experimental base self-built by Zhiyuan. It is equipped with: 1) Multimodal sensors, including 8 surrounding cameras, a 6-degree-of-freedom dexterous hand, a six-dimensional force sensor, a high-precision visual-tactile sensor, etc., supporting millimeter-level fine operations (such as installing memory modules and arranging tableware); 2) A mobile dual-arm robot platform with 32 degrees of freedom throughout the body, suitable for dynamic perception and execution of complex tasks.
Core Features
Diverse task coverage: The AgiBot World dataset includes more than eighty kinds of diverse skills in daily life. Ranging from basic operations such as grasping, placing, pushing, and pulling to more complex actions like stirring, folding, ironing, etc., it almost encompasses most of the movement requirements needed in daily life.
Real scenarios across the entire domain: The dataset was born in the large-scale data collection factory and application experiment base self-built by Zhiyuan Robotics. The total spatial area exceeds 4,000 square meters, containing more than three thousand kinds of real objects. It replicates five core scenarios including home, catering, industry, supermarkets, and offices, providing a highly realistic production and living environment for robots.
All-round hardware platform: The robot platform relied on for dataset collection is equipped with an 8-camera surround layout, which can perceive the dynamic changes of the surrounding environment in real-time and from all aspects. The robot also has a dexterous hand with 6 active degrees of freedom, enabling it to complete various complex operations such as ironing clothes. With up to 32 degrees of freedom throughout the body and the configuration of a six-dimensional force sensor at the end and a high-precision visual-tactile sensor, the robot can perform tasks in an orderly manner when facing fine operation tasks.
Full-process quality control: During the collection process of AgiBot World, Zhiyuan Robotics has adopted a strategy of multi-level quality control and full-process human-in-the-loop. From the professional training of collectors, strict management during the collection process to the screening, review, and annotation of data, every link has been meticulously designed and strictly controlled.
Dataset content: The AgiBot World dataset includes more than eighty kinds of diverse skills in daily life, from basic operations such as grasping, placing, pushing, and pulling to complex actions like stirring, folding, ironing, etc., almost covering most of the action requirements needed in human daily life.
02
Open X-Embodiment
Open X-Embodiment is a robotic learning dataset jointly launched by Google DeepMind, Stanford University and 21 other institutions worldwide on June 1, 2024. It is also the largest open-source real-robot dataset to date.

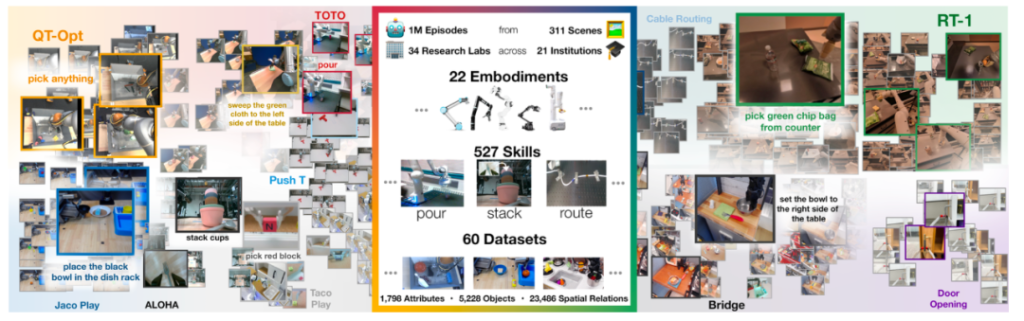
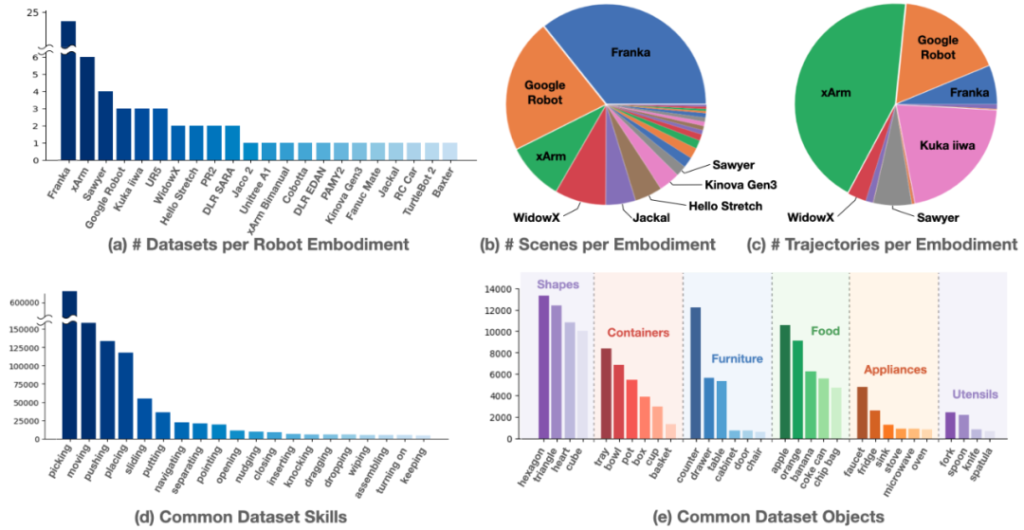
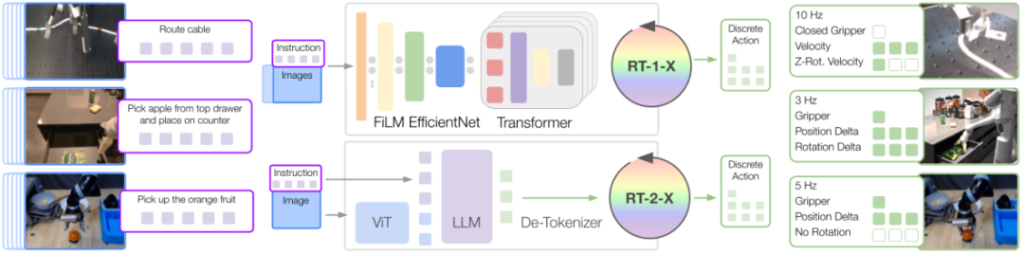
Data Source and Scale: It integrates data from 22 different robot platforms of multiple research institutions around the world, brings together 60 existing datasets, contains over 1 million real robot trajectories, covers 527 skills, involves 160,266 tasks, and the data volume is approximately 3600G.
Data Processing: All source datasets are uniformly converted into the RLDS format. For datasets with multiple viewpoints, only one “canonical” viewpoint image is selected, the image is resized to 320×256, and the original actions are converted into actions of the EE.
Robot Types and Skill Scenarios: It involves various types of robots such as single-arm, dual-arm, and quadruped robots. The skills mainly focus on pick-place, and also include more difficult skills such as wiping and assembling. The scenarios and the objects being manipulated are concentrated in home and kitchen scenes, as well as items such as furniture, food, and tableware.
Core features
Diversity: It covers a variety of robot platforms and a wide range of task types. The mixing of data from different robots makes it possible to train more general robot strategies.
Standardization: It uses the unified RLDS data format and supports various action spaces and input modes of different robot setups, facilitating consumption by downstream applications.
Large Scale: As one of the largest datasets in the field of robot learning so far, its large data volume helps improve the performance and generalization ability of models.
Ease of Use: It provides a self-contained colab, allowing users to visualize partial “episodes” in each dataset through this colab and create data batches for training and inference.
Openness: It adopts the dual licensing of Apache 2.0 and CC-BY, ensuring the openness and reusability of the project and promoting cooperation and innovation in the field of robotics within the open-source community.
03
DROID
DROID (Distributed Robot Interaction Dataset) is a large – scale robot interaction dataset co – created by 13 research institutions including Stanford University.


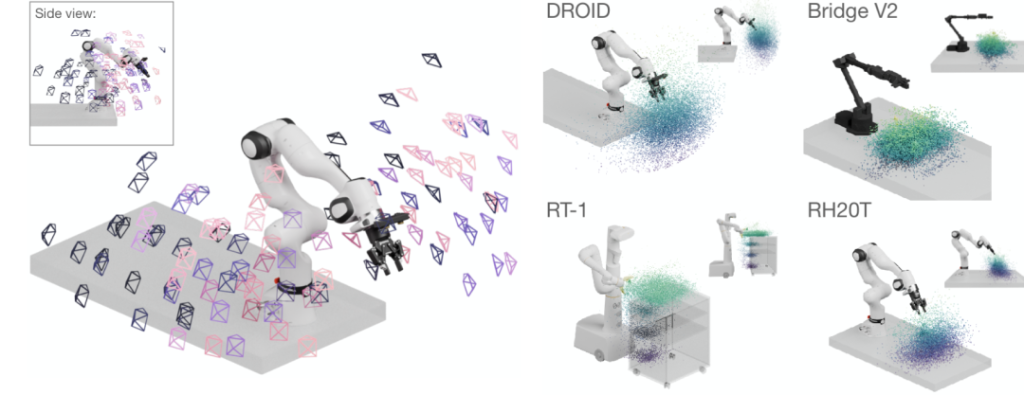
Basic situation
Data Scale: It contains 76,000 robot demonstration trajectories, approximately 350 hours of interactive data, covering 86 tasks and 564 scenarios, with a large amount of data.
Data Source: Within 12 months, 50 data collectors from North America, Asia, and Europe used 18 robots for distributed data collection.
Data Content: Each data entry includes three synchronous RGB camera streams, camera calibration information, depth information, natural language instructions, as well as the proprioceptive state and actions of the robot, etc.
Data Format: It has a standardized data format, including parts such as “episode_metadata” and “steps”, which record in detail various information of each operation step.
Core features: 1) High degree of diversity
Diverse Scenarios: It covers various real environments such as offices, laboratories, kitchens, bathrooms, etc., with a total of 564 scenarios, far exceeding previous datasets. This enables robots to learn operation knowledge in different environments.
Abundant Tasks: It includes 86 basic actions such as grasping, placing, switching on and off, etc. Each action has a large number of combinations of different objects and scenarios, which helps robots learn general operation skills.
Wide Range of Perspectives: It includes 1417 camera perspectives. During the data collection process, the robot can move freely in the workspace, recording operation data at various positions in the workspace, not limited to fixed areas such as desktops.
Core features: 2) High quality of the data
Hardware Standardization: All data collection points use the same hardware configuration, such as Franka Panda robotic arms, Robotiq grippers, three stereo vision cameras, etc. These devices are installed on movable brackets, facilitating rapid deployment across different scenarios and ensuring the consistency of data collection.
Standardized Collection Process: A specialized data collection GUI interface has been developed. It randomly prompts operators to perform different tasks and regularly requires changes in camera positions, lighting adjustments, etc., increasing the variability of the data. At the same time, the operation trajectories are screened and filtered to remove incomplete or poor-quality data.
Complete Annotation: Each operation trajectory is accompanied by natural language instruction annotations, and complete information such as camera calibration and robot status is recorded, making it convenient for researchers to use.
Multimodal Fusion: It covers data from multiple modalities such as visual images, depth maps, text instructions, robot status, and actions, providing rich materials for the development and verification of multimodal fusion algorithms, and is suitable for various tasks such as object detection, semantic segmentation, and pose estimation.
Core features: 3) Openness and ease of use
Open-source Resources: The complete dataset is open-sourced under the CC-BY 4.0 license. It also provides interactive dataset visualization tools, codes for training generalizable strategies, pre-trained strategy checkpoints, and detailed guidelines for replicating the robot hardware setup and control stack, reducing the research threshold.
Structured Design: The structured design of the dataset makes the data loading and processing more convenient. Researchers can select specific data subsets for experiments according to their needs.
Improved Model Performance: Experiments show that the models trained with DROID have significant improvements in aspects such as success rate, robustness, and generalization ability. In six test tasks, compared with models trained only with task-related data, the models trained in combination with DROID have an average success rate improvement of 22%, and perform better in out-of-distribution sample scenarios.
04
RT-1
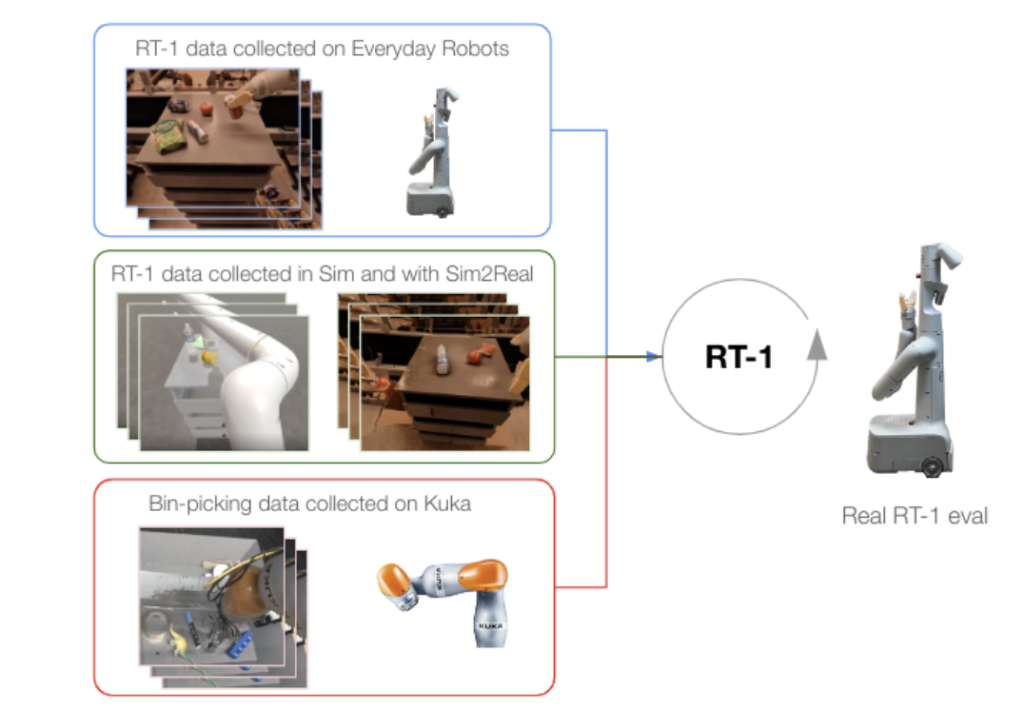
The RT-1 dataset was proposed by Google researchers in 2022. It is a large-scale real-world robotic dataset used for training the RT-1 model.

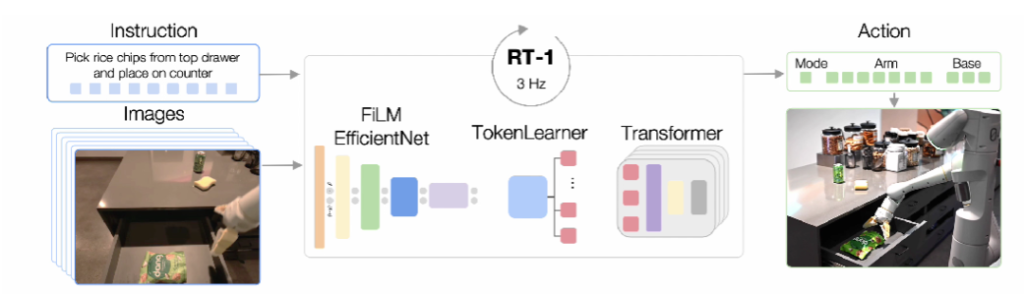

Basic situation
Data Scale: Within 17 months, 130,000 segments were collected using 13 EDR robotic arms. Each segment contains 6 images with a resolution of 300×300, as well as information such as corresponding actions and text instructions. The data volume reaches 111.06GB, covering more than 700 tasks.
Data Source: The data was collected when the mobile manipulation robots of Everyday Robots were performing tasks. Each robot is equipped with a 7-degree-of-freedom robotic arm, a two-finger gripper, and a mobile base.
Data Content: The dataset includes demonstrations of various tasks, such as picking up and placing items, opening and closing drawers, taking items out of and putting items into drawers, vertically placing slender items, etc. Each segment is also text-annotated to represent its action instructions.
Core features
o Multimodal Fusion: It tightly integrates visual information, natural language instructions, and robot actions. The model takes short sequences of images and natural language instructions as input and outputs the robot’s actions at the current moment, including the movements of the robotic arm and chassis as well as mode conversion instructions, enabling the robot to better understand and execute tasks.
o Strong Generalization Ability: In the zero-shot setting, RT-1 can complete 76% of instructions it has never seen before, far exceeding the baseline model. It also demonstrates strong robustness in interference tasks and background tasks, successfully completing 83% of interference robustness tasks and 59% of background robustness tasks.
Real-time Inference Ability: By compressing the original tokens through TokenLearner and retaining the instruction image tokens corresponding to the previous five frames of images, the model can perform efficient inference during runtime to achieve real-time control, accelerating the inference speed by 2.4 times and 1.7 times respectively.
o High Scalability: Introducing data from different robots, even if these data come from completely different domains, can further improve the model performance. For example, mixing the data of the Kuka IIWA robot with RT-1 data for training significantly improves the model’s performance in the box grasping task.
o Openness and Breadth: The dataset covers a variety of tasks and settings, featuring good openness and breadth, enabling the robot to learn general operation patterns and adapt to new tasks and environments.
05
BridgeData V2
BridgeData V2 is a large – scale robotic manipulation behavior dataset jointly released by the University of California, Berkeley, Stanford University, Google DeepMind, and Carnegie Mellon University in 2023.


Data Scale: It contains 60,096 trajectories, which are divided into 50,365 expert demonstrations and 9,731 pieces of autonomously generated data.
Data Source: The data is collected in 24 different environments, covering various scenarios such as kitchens and desktops. The objects, camera positions, and workspace positioning in these scenarios are all different.
Data Content: It includes 13 skills, such as pick-and-place, pushing, sweeping, stacking, folding, etc., and more than 100 different objects. Each trajectory is accompanied by natural language instructions, and some of the data includes multi-camera perspectives and depth data.
Robot Type: Based on the low-cost WidowX 250 single-arm robot, it is equipped with multi-view RGB-D cameras and VR teleoperation devices.
Core Features: 1) Diversity and Openness
Diversity of Environments and Tasks: The dataset covers 24 environments and 13 skills. The rich variations in environments and tasks enable robots to learn general operation patterns and adapt to new tasks and environments.
Open Vocabulary and Multi-task Learning: The dataset supports task specifications with an open vocabulary, allowing for conditional learning through target images or natural language instructions, and is compatible with various multi-task learning methods.
Core Features: 2) Multimodal Fusion
Multimodal Data: The dataset contains multimodal information such as multi-view RGB-D images, robot joint states, and language labels, providing rich materials for the development and verification of multimodal fusion algorithms.
Core Features: 3) Practicality and Ease of Use
Low Cost and Easy Accessibility: The data is collected based on the low-cost WidowX 250 robot, and all devices can be publicly purchased, reducing the research threshold.
Annotation: All data includes natural language labels, and the trajectories are post-labeled through a crowdsourcing platform, facilitating language conditional settings and task analysis for researchers.
Core Features: 4) Generalization Ability
Generalization across Environments and Institutions: It emphasizes the generalization ability of skills, and the learned skills can be applied to new objects and environments, even across different institutions.
Robustness and Reliability: By collecting data under various environmental conditions, the robustness and reliability of the robot are enhanced.
06
RoboSet
The RoboSet dataset was released by Carnegie Mellon University and FAIR – MetaAI in September 2023. It is a large – scale real – world multi – task dataset in the field of embodied intelligence.



Basic situation
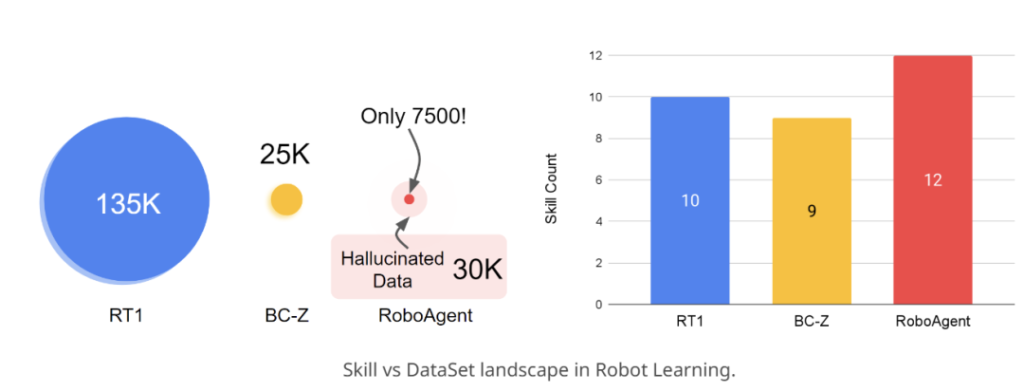
Data scale: It contains 28,500 trajectories, covering 38 tasks. Each trajectory is generated through human teleoperation or kinesthetic demonstration.
Data source: The data is collected through kinesthetic demonstrations and teleoperation demonstrations. Among them, 9,500 trajectories are collected through teleoperation, and 19,000 trajectories are collected through kinesthetic replay.
Scenarios and tasks: It mainly focuses on daily kitchen activity scenarios, such as making tea, baking, etc., covering 12 action skills.
Data collection: The Franka-Emika robot equipped with a Robotiq gripper is used to collect data through human teleoperation. Daily kitchen activities are decomposed into different subtasks, and the corresponding robot data is recorded during the execution of these subtasks.
Core Features
1)Diversity and Openness.Data Diversity: The dataset includes multi-task activities, with four different camera views per frame and scene variations for each demonstration, ensuring visual diversity.
Task Diversity: It covers 12 action skills across 38 tasks, and each task is defined through language instructions, providing opportunities for language-guided serialization and generalization.
2)Multimodal Fusion.The dataset contains information in multiple modalities, including visual images, language instructions, and robotic actions, providing rich materials for the development and verification of multimodal fusion algorithms.
3)Generalization Ability.Cross-scene Generalization: By collecting data in multiple scenarios, it enhances the robot’s generalization ability in new scenarios.
Task Generalization: Trained with only 7,500 trajectories, it demonstrates a general-purpose RoboAgent that can showcase 12 operation skills across 38 tasks and generalize them to hundreds of different unseen scenarios.
Practicality and Ease of Use
Multi-view Data: There are four different camera views per frame, which helps downstream policy learning, making the visual representation independent of specific viewpoints and enhancing robustness to viewpoint changes.
Open Source and Accessibility: The open-source nature of the dataset and detailed documentation reduce the barriers for researchers to use it.
07
BC-Z
The BC-Z dataset was jointly developed in 2022 by Google, Everyday Robots, the University of California, Berkeley, and Stanford University. It is a large-scale robotic learning dataset aimed at advancing the field of robotic imitation learning.

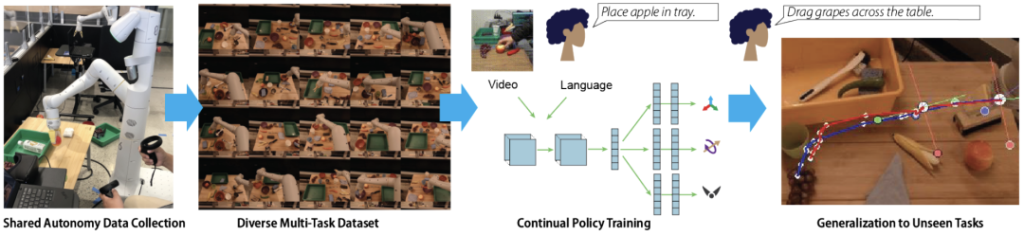

Basic situation
Data scale: It includes more than 25,877 different operation task scenarios, covering 100 diverse operation tasks, involving 12 robots and 7 different operators. The cumulative robot operation time amounts to 125 hours. Additionally, 18,726 human videos of the same tasks have been collected.
Data source: It is collected through expert-level remote operation and shared autonomous processes.
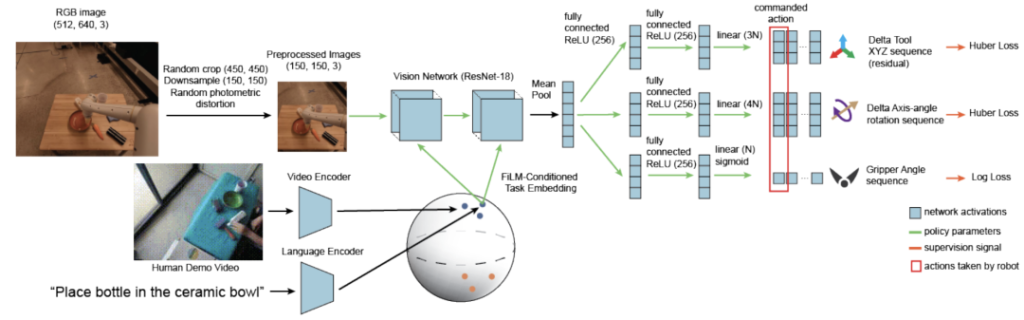
Data content: Each task comes with corresponding language descriptions or human operation videos. The dataset supports training a multi-task strategy with 7 degrees of freedom, which can be adjusted according to the language descriptions of the tasks or human operation videos to perform specific operation tasks.
Core features
Zero-shot Task Generalization Ability: The core contribution of this dataset is to support zero-shot task generalization, which means enabling robots to perform new operation tasks through imitation learning without prior experience. Through a large-scale interactive imitation learning system, flexible task embedding, and diverse data, zero-shot generalization on unseen tasks is achieved.
Unique Data Collection Method: The data collection starts from the initial expert stage, where humans provide task demonstrations from start to finish. After learning the initial multi-task strategy from expert data, demonstrations are continuously collected in the “shared autonomy” mode. In this mode, the current strategy attempts to execute tasks, and humans supervise and can intervene to provide corrections when the robot makes mistakes. This process is similar to the Human-Gated DAgger (HG-DAgger) algorithm.
Multimodal Fusion: The dataset contains information of multiple modalities, including visual images, language instructions, and robot actions. The encoder q(z|w) takes language commands or human videos as input and generates task embeddings z. Then, the task embeddings z are combined with visual images s, and actions a are generated through the control layer π, realizing multimodal fusion.
Flexible Task Specification Form: The system flexibly adjusts its strategy according to different forms of task specifications, including language instructions or videos of people performing tasks. Different from discrete one-hot task identifiers, these continuous forms of task specifications can, in principle, enable robots to generalize to new tasks with zero-shot or few-shot learning by providing language or video commands of new tasks during testing.
Strong Scalability and Practicality: The BC-Z dataset has strong scalability and can be used to train multi-task strategies, and it can adapt to various different tasks and scenarios. Its research achievements are not only of great academic significance but also provide new ideas and methods for robot operations in practical applications, promoting the development of robot technology.
08
MIME
The MIME dataset was released by the Robotics Institute of Carnegie Mellon University in October 2018 and is one of the datasets in the field of embodied intelligence.



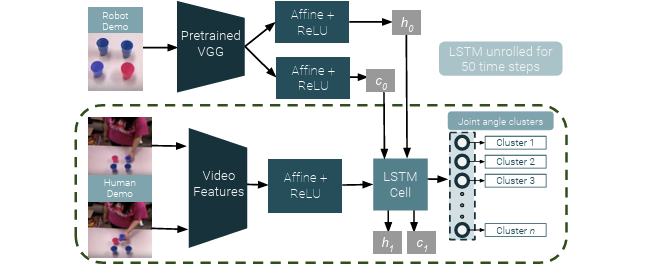
Data Scale: It contains 8,260 human-robot demonstrations of more than 20 different robot tasks, consisting of videos of human demonstrations and kinesthetic trajectories of robot demonstrations.
Data Source: Multiple data collection techniques are utilized, including kinesthetic teaching and visual demonstrations, to collect human-robot interaction data. Data collection is carried out using a Baxter robot in the gravity-compensated kinesthetic mode. This robot is a dual-arm manipulator equipped with two-finger parallel grippers, and it is also equipped with a Kinect mounted on the robot’s head and two SoftKinetic DS325 cameras, with each camera installed on the robot’s wrist.
Core features
Abundant Interactive Action Data: It covers a variety of interactive actions, enabling robots to learn a series of coherent actions ranging from simple tasks like pushing objects to difficult tasks such as stacking household items, thus better enabling them to complete complex tasks and understand the sequence and logical relationships of tasks.
Multi-view Data: Thanks to the head-mounted camera and wrist-mounted cameras, data can be obtained from multiple perspectives. This helps robots better understand tasks and the environment, enhances their robustness to changes in different perspectives, and provides materials for the development and verification of multi-view fusion algorithms.
Multimodal Fusion: The dataset contains information from multiple modalities such as visual images, human demonstration videos, and robot kinesthetic trajectories, providing rich materials for the development and verification of multimodal fusion algorithms.
Promoting Robot Imitation Learning: It provides sufficient samples for robot imitation learning. Traditional learning methods have limitations when dealing with complex interactive action tasks. The large number of rich samples in the MIME dataset helps robots learn various situations and action patterns, thereby enhancing their generalization ability and enabling them to better handle complex and changeable tasks in real scenarios.
09
ARIO
The ARIO (All Robots In One) dataset was released by Peng Cheng Laboratory, Southern University of Science and Technology, Sun Yat – sen University, etc. in August 2024. It is a large – scale unified dataset in the field of embodied intelligence.

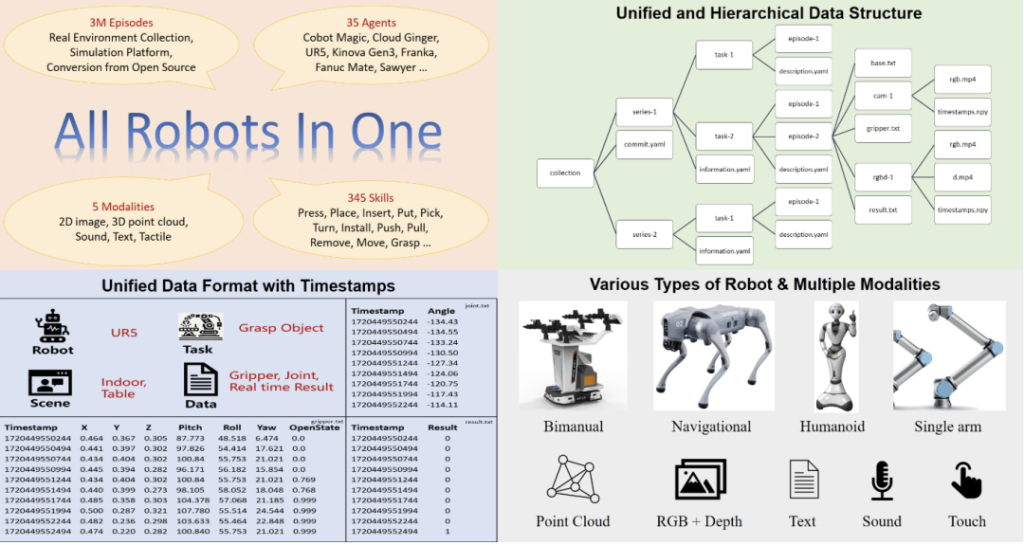
Basic situation
Data Scale: It contains 258 series, 321,064 tasks and 3,033,188 segments.
Data Source: Firstly, data is collected by real people through arranging scenes and tasks in real environments. Secondly, virtual scenes and object models are designed based on simulation engines such as MuJoCo and Habitat, and data is generated by driving the robot model through the simulation engine. Thirdly, the currently open-source embodied datasets are analyzed and processed one by one and converted into data conforming to the ARIO format standards.
Core features
Multimodal Fusion: It supports five sensory modalities, including 2D images, 3D vision, sound, text, and touch, providing robots with richer and more diverse perceptual data and enhancing their perception and interaction capabilities.
Unified Data Standard and Architecture: A set of format standards for large-scale embodied data has been designed, which can record robot control parameters in various forms. The data organization is clear, and it can be compatible with sensors of different frame rates and record the corresponding timestamps. The dataset adopts a hierarchical structure of scene-task-segment, and each scene and task has detailed text descriptions.
Integration of Simulated and Real Data: It combines simulated and real-world data, enhancing the generalization ability across different hardware platforms and contributing to the research on the transition from simulation to reality.
Timestamp-aligned Data Processing: Data is recorded and synchronized based on timestamps to adapt to the frame rates of different sensors, ensuring the accuracy and consistency of the data and supporting the effective integration of multimodal data.
Diversity and Richness of Data: The scenes cover desktops, open environments, multi-room settings, kitchens, housework scenarios, corridors, etc. The skills cover pick, place, put, move, open, grasp, etc. It integrates multiple data sources, preprocesses a large number of open-source datasets, and standardizes the format to ensure seamless integration and usage.
10
RoboMIND
RoboMIND is a multi – embodiment intelligence normative dataset jointly created by institutions such as the Beijing Innovation Center for Humanoid Robotics Laboratory and the State Key Laboratory of Multimedia Information Processing at Peking University.




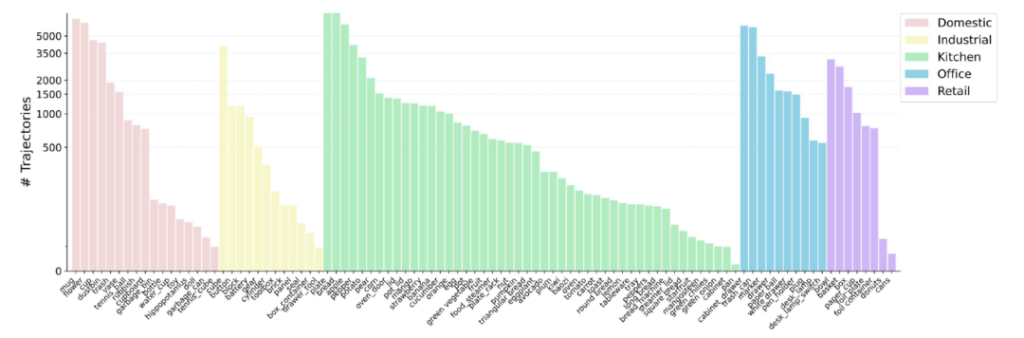
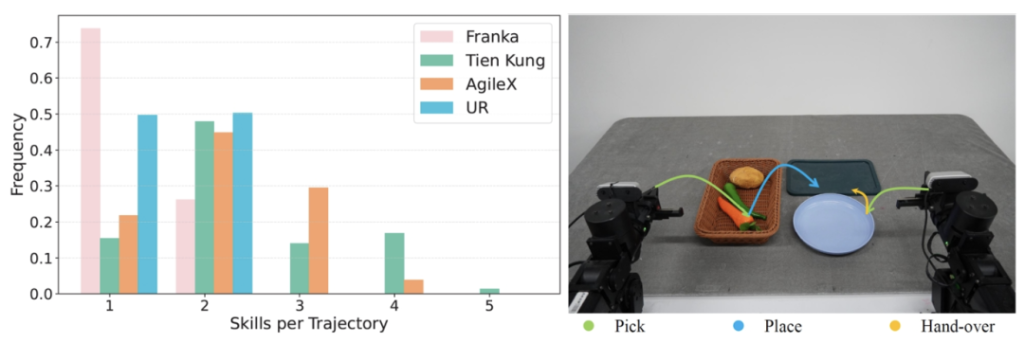
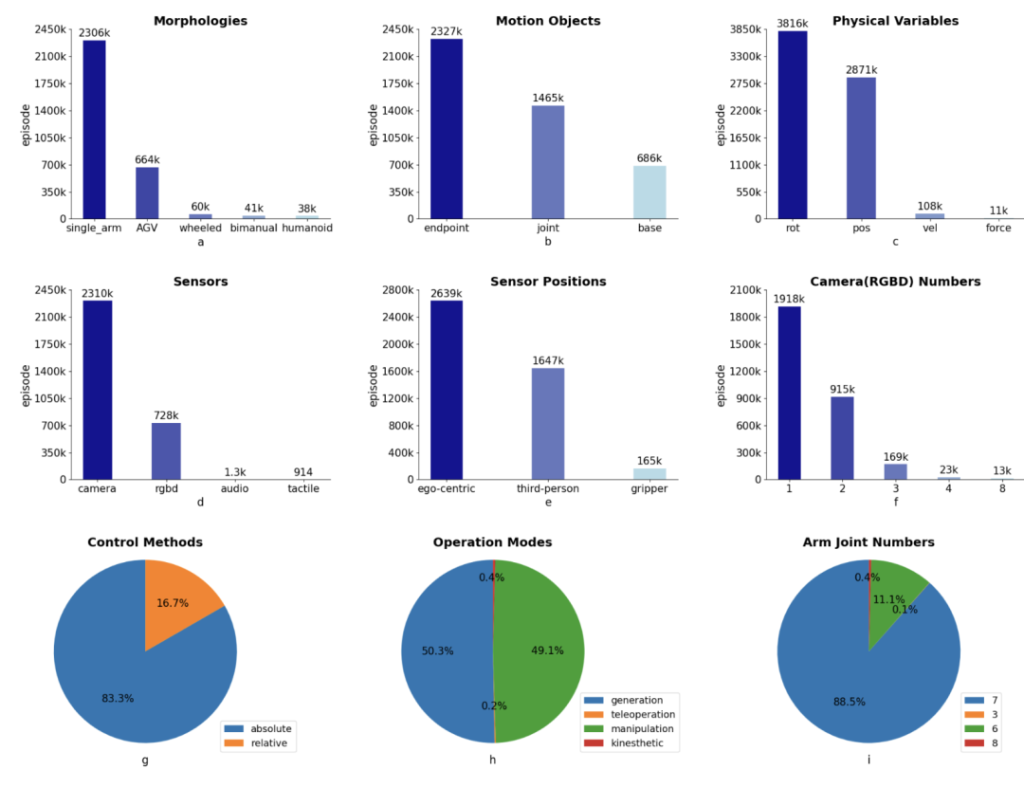
Basic situation
Data Scale: It contains 55,000 real-world demonstration trajectories, covering 279 diverse tasks and 61 different object categories.
Data Source: The data is collected through manual remote operation, ensuring the consistency and reliability of the data.
Core features
Multimodal Fusion: The dataset encompasses information from multiple modalities, including multi-view RGB-D images, perception state information of the robot itself, details of the end-effector, and linguistic descriptions of tasks. This provides robots with rich perceptual and comprehension data.
Diverse Robot Morphologies and Task Coverage: It covers four different robot morphologies, such as single-arm robots, dual-arm robots, humanoid robots, and dexterous hands, along with simulation data in the digital twin environment. The task types range from basic operations to complex long-sequence tasks, involving 61 different object categories and covering multiple scenarios like home, kitchen, industrial, office, and retail environments.
Unified Data Collection Platform and Standardized Protocol: It is based on a unified data collection platform and standardized protocol, ensuring the consistency and reliability of the data, which makes it convenient for researchers to use directly.
Inclusion of Failure Cases: In addition to successful operation trajectories, 5,000 failure cases and their detailed reasons are recorded, providing valuable learning resources for the improvement of robot models and helping to enhance the performance of models in the real world.
Digital Twin Environment: A digital twin environment has been created in the Isaac Sim simulator, which can generate additional training data at a low cost and support efficient evaluation, further enriching and expanding the diversity of the dataset.
High-quality Linguistic Annotations: Fine-grained linguistic annotations are provided for 10,000 successful robot motion trajectories, accurately capturing the operation steps and relevant contexts, improving the precision and reliability of linguistic annotations.
Efficient Data Management and Processing: An intelligent data platform has been developed, using a cloud-native architecture and distributed computing to handle large-scale data and providing functions such as data collection, storage, management, and processing analysis.
11
RH20T
RH20T is a large-scale dataset for embodied intelligence, which was released by Shanghai Jiao Tong University in July 2023.


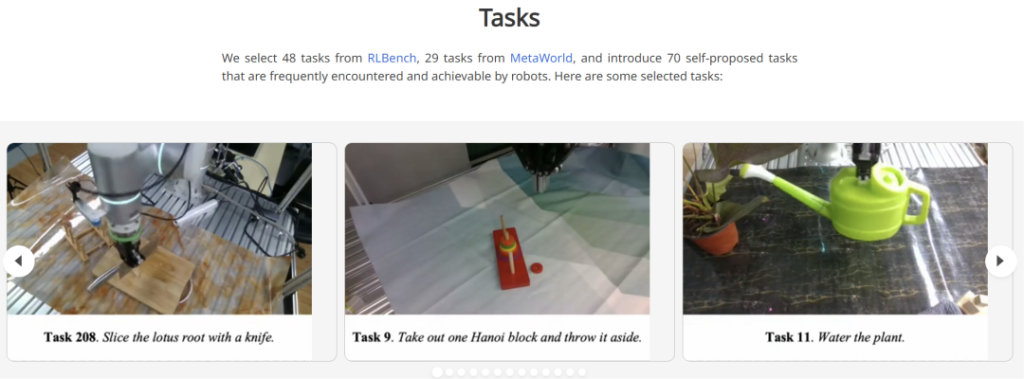

Data Scale: It contains over 110,000 robot operation sequences with rich contacts, covering diverse skills, environments, robots, and camera viewpoints. Each task includes millions of “human demonstration – robot operation” pairs, and the data volume exceeds 40TB.
Skill Scope: Researchers have selected 48 tasks from RLBench and 29 tasks from MetaWorld, and introduced 70 self-proposed tasks. These tasks include complex actions that require rich contact interactions such as cutting, inserting, slicing, pouring, folding, and rotating.
Data Sources: The data is collected through manual remote operation, emphasizing intuitive and accurate remote operation. Data collection is carried out using robotic arms equipped with torque sensors, grippers, handheld cameras, global cameras, microphones, tactile devices, etc.
Core features
Multimodal Fusion: Each sequence incorporates visual, force sensing, audio, and motion information, along with corresponding human demonstration videos and language descriptions. This provides robots with comprehensive perceptual data, facilitating their better understanding and execution of tasks.
Multiple Perspectives and Various Robot Morphologies: The dataset includes visual data from multiple perspectives. Data collection is carried out using various types of robots, such as single-arm robots and dual-arm robots, which enhances the diversity of the data and the generalization ability of the models.
Rational Data Organization Structure: The dataset is organized according to the hierarchical structure of tasks, making it convenient to construct a large number of “human demonstration – robot operation” pairs. This is helpful for models to learn the semantics and execution methods of tasks.
High-quality Data Collection and Processing: All sensors are precisely calibrated to ensure the high quality of the data. Meanwhile, the data is preprocessed, including coordinate system alignment, torque sensor weighting, etc., to provide a consistent data interface.
Emphasis on Operations with Rich Contacts: Different from previous datasets that focus on vision-guided control, the RH20T places importance on robots’ operations with rich contacts. By equipping torque sensors and tactile devices, robots are enabled to learn how to handle tasks that require tactile feedback.
Support for Few-shot Learning: The design goal of the dataset is to enable robots to acquire new skills in unfamiliar environments with minimal data, which helps to promote the development of advanced technologies such as one-shot imitation learning.
Rich Dataset API and Application Scenarios: The dataset provides an API interface, including data extraction scripts, scene data loaders, online preprocessors, etc., making it convenient for researchers to use the dataset for model training and testing. At the same time, the dataset has advantages in algorithm accumulation across multiple domains, which can drive the widespread application of embodied intelligence in various fields.